Sincronizando banco de dados offline com online utilizando API REST no modelo de Ordem de Serviço


Veja neste exemplo como técnicos in loco podem atualizar ordens de serviço de forma offline e sincronizar com a matriz mantendo a integridade dos dados
Salve salve moqueridos, nessa aula vamos ver como fazer a abstração de determinado problema e como que podemos fazer para desenvolver uma solução.
O problema que vamos colocar aqui, foi uma solicitação do nosso aluno com um pedido no UpInside Play. É um assunto bem interessante e por mais que possa parecer bem complexo a resolução, você vai notar que com organição fica bem tranquilo o desenvolvimento.
Sem mais delongas...
Situação Problema
A necessidade aqui é que há o seguinte cenário:
Ele possui uma central de atendimento (online) e irá disponibilizar um notebook para determinados técnicos para que possam ser abertas Orderns de Serviço. Esse ambiente dos tecnicos terá uma instalação do XAMPP por exemplo (pacote PHP, MySQL, Apache...) e não possuirá comunicação com a internet a todo momento.
Portanto, é necessário que esse sistema local posteriormente possa/deva ser sincronizado com a central de atendimento.
Isso é o que foi reportado na solicição, mas se pegarmos para ver como funciona a lógica chegamos a conclusão de que não é bem assim que funciona.
Abstração
Se você pegar uma outra empresa que tem esse mesmo tipo de serviço, o fluxo não é bem assim!
Olha a NET (Empresa que fornece TV a cabo, internet, telefonia...) por exemplo, o fluxo basicamente é o seguinte:
Você vai entrar em contato com a central de atendimento ao cliente (e ficar alguns minutos na linha escutando diversas opções) e quando conseguir falar com um atendente, ela vai coletar alguns dados sobre você e o seu problema.
Posteriormente, o técnico da NET vai abrir o sistema e pegar as Orderns de Serviço que ele tem para cumprir naquele dia.
Então veja que na real não é o técnico que faz a abertura, é a central que alimenta o sistema e o técnico simplesmente consome e pode ter algumas alterações... Requisição de Materiais, Notas, Laudos, Fechamento da OS... Enfim, determinadas ações, mas não a criação.
Com isso a gente chega a conclusão de que precisamos criar alguns caminhos de ida e volta dos dados, e para resolver esse problema podemos criar endPoint's específicos para fazer a comunicação entre os dois sistemas.
Não vou entrar no mérito de como as aplicações foram criadas aqui no artigo... A gente faz um overview na aula de cada um dos sistemas e eu mostro como ficou a arquitetura dos projetos, as tecnologias utilizadas, mas tudo é bem simples!
O mais importante dessa aula é compreender a organização do fluxo dos dados! Para isso, criei um PDF contendo a abstração que fiz disponibilizados de duas maneiras diferentes... Aí ficar a seu critério identificar qual a que mais faz sentido para você :)
Esse material vai estar dentro do nosso repositório no GitHub! O link vai estar aqui abaixo.
Comunicação
Como ja informei, podemos resolver o problema usando API! Para isso, eu vou ter que te convidar a assistir a nossa aula de criação de endPoint que está disponível no UpInsidePlay (somente para membros do Club).
Nessa aula sobre a criação do primeiro endPoint, eu te mostro algumas funções básicas, criamos a classe da API, padronização de erros, autenticação de usuário e o consumo com o Postman.
A API que desenvolvi nessa aula, pode obviamente ser consumida pelo Postman também! Saca só como fica o consumo :)
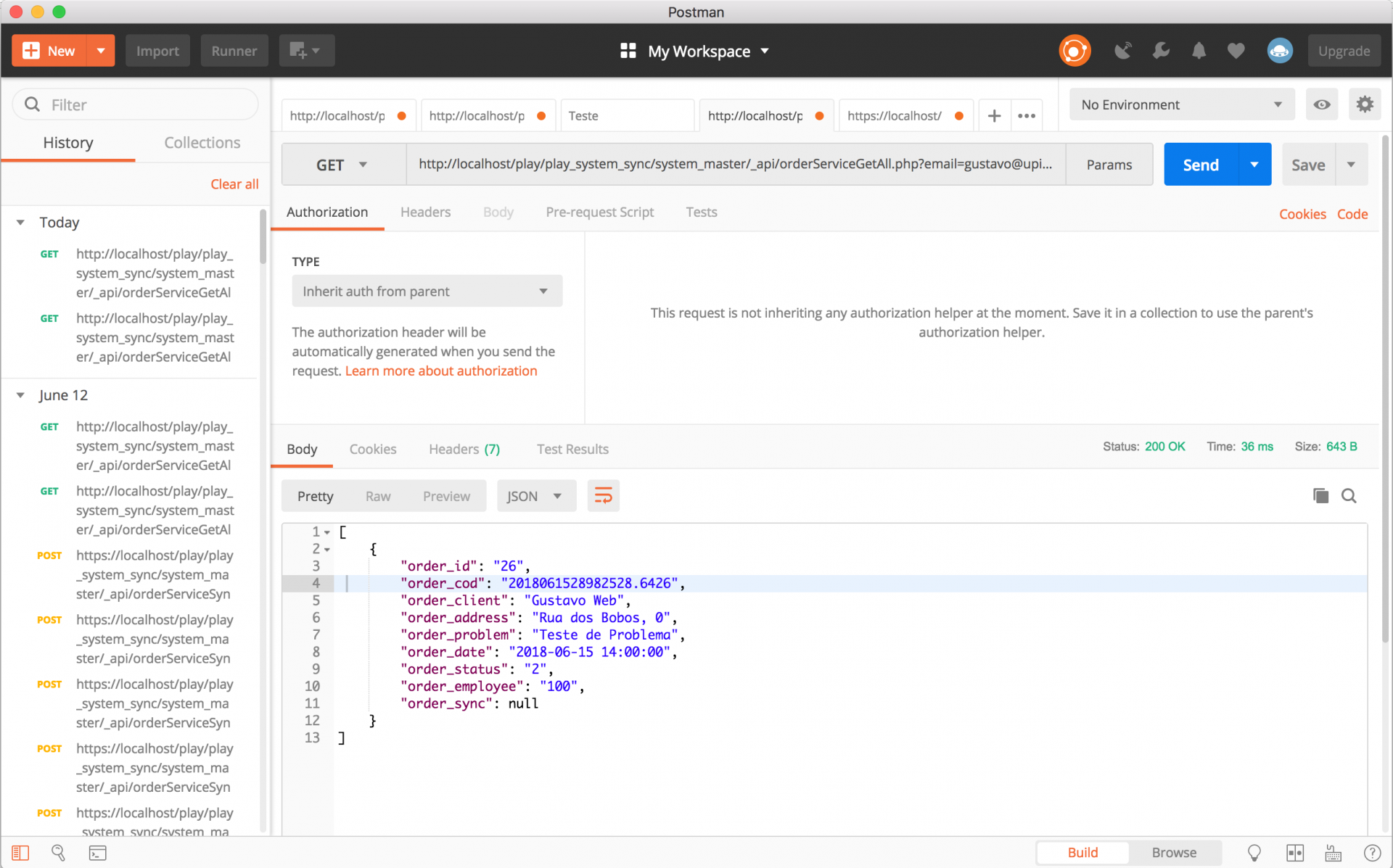
Se você nunca trabalhou com o Postman, é um aplicativo que você usa para fazer requisições para outros endereços utilizando vários verbos (GET, POST, PUT, DELETE....)
Então a ferrmenta nos auxilia durante o debug das informações.
Se você ver pegar para entender o PDF que citei, vai ver que a comunicação entre o MASTER e o SLAVE são exatamente 3 caminhos, e temos os mesmo 3 endPoints.
MASTER é o nome carinhoso que eu sei para o sistema que a central de atendimento trabalha. É onde concentra todas as informações.
O SLAVE é o sistema local que vai estar instalado na máquina do técnico.
Segurança e Isolamento
Em nenhum momento, um banco tem acesso ao outro, ou as senhas são expostas na aplicação. Óbviamente que o sistema local tem o seu acesso com o banco de dados, mas ele não terá acesso direto a base MASTER.
Portanto, a parte de senhas você pode ficar tranquilo. A autenticação da API pode ser usado o e-mail do tecnico junto com um token, senha, código de sessão... Fica a seu critério.
Como a autenticação da API é baseada por usuário, isso cria uma certa camada de isolamento. O que quero dizer com isso é que o técnico vai ter acesso somente as Orderns de Serviço que forem designadas para ele.
Material de Apoio
Aqui não tivemos nenhuma documentação para usar como base, mas você pode querer assistir a aula sobre como criar o seu primeiro endPoint. Para isso é só você clicar aqui e eu te levo pra lá :)
Aqui abaixo eu vou deixar o link para o repositório lá no nosso github. Vamos para algumas informações:
Há dois diretórios... Um _master e outro _slave que eu não preciso te falar o que contém cada um deles né? :P
A API está dentro do _master. Afinal é o central que vai ter os pontos de entrada e saída de informação... Mais fácil colocar tudo isso num único lugar do que ter dezenas, centenas, milhares de API's em cada _slave.
O código desenvolvido não foge nada do que já trabalhamos no dia a dia. Temos um banco de dados MariaDB criado com duas tabelas bastante simples, cada um com sua devida estrutura. O DUMP do banco está na raiz de cada sistema! Se precisar alterar qualquer parâmetro de conexão com o banco, é só abrir o config.php de cada aplicação e colocar de acordo com a sua necessidade.
Nem fiz o uso do composer para ficar mais simples.
As requisições estão sendo tratadas via ajax! Portanto, os gatilhos estão dentro do script.js :)
Há também o PDF da abstração que vale a pena ser consultado. Afinal a programação é fácil! Saber o que fazer com ela é que é o difícil, e nesse caso, basta organizar certinho as informações que fica tranquilo desenvolver.
Link para o repositório lá no GitHub!
Atualizar arquivos do SLAVE
Aqui a gente não entra muito no mérito porque pode até fugir da programação WEB! A solução mais "simples" que vem a cabeça é ter um .bat ou um .sh na máquina SLAVE e esse processo ficar responsável por se conectar a um repositório GIT, FTP, SFTP, Mapeamento de Rede (ou qualquer outro meio que você tenha a disposição) e fazer o "download" dos arquivos e atualizar na pasta base do sistema...
Não é um processo muito tranquilo de se fazer, tem toda a questão de permissão, sobrescrever os arquivos corretos, gerar um backup do sistema previamente, ter um plano de contigência...
Ou ainda, a solução que para mim é a mais correta, o técnico "encostar" o notebook a cada X tempo para que possa ser feito a atualização por um programador! Assim você pode rodar rotinas de integridade de banco de dados, efetuar os testes de comunicação e garantir que o sistema _slave está apto para ele trabalhar sem problemas.
Esse X tempo vai depender de acordo com a demanda. Pode ser uma vez por ano, uma vez a cada 6 meses... Se for mais do que isso, talvez a opção seja automatizar mesmo! Nem que seja sob a supervisão de um programador, mas algo que você pode colocar para fazer e não se preocupar. Depois você só volta e testa para garantir o funcionamento :)
Veja também:
Confira mais artigos relacionados e obtenha ainda mais dicas de controle para suas contas.

Efetue pesquisa dinâmica com duas entradas de informações e filtre os registros utilizando o operador LIKE

Desenvolvendo Login Step by Step com Ajax e PHP
Apresente boas vindas ao usuário antes mesmo de solicitar a senha sem precisar recarregar a página
